by zhangxinxu from https://www.zhangxinxu.com/wordpress/?p=11124 鑫空间-鑫生活
本文欢迎分享与聚合,全文转载就不必了,尊重版权,圈子就这么大,若急用可以联系授权。

一、以为很简单,结果…
遇到需求,需要对音频倍速合成,可能是0.5倍速,也可能是2倍速。
这还不简单,0.5倍速那就采样的时候两两重复,2倍速间隔取样就好了,相关代码如下所示(假设音频地址是url,播放速率变量是rate):
fetch(url)
.then(response => response.arrayBuffer())
.then(arrayBuffer => new AudioContext().decodeAudioData(arrayBuffer))
.then(originAudioBuffer => {
// 创建新的AudioBuffer
const audioBuffer = new AudioContext().createBuffer(
originAudioBuffer.numberOfChannels,
originAudioBuffer.length / rate,
originAudioBuffer.sampleRate
);
// 复制原始音频的数据到新的AudioBuffer
for (let channel = 0; channel < originAudioBuffer.numberOfChannels; channel++) {
const originChannelData = originAudioBuffer.getChannelData(channel);
const newChannelData = audioBuffer.getChannelData(channel);
for (let i = 0; i < audioBuffer.length; i += 1) {
newChannelData[i] = originChannelData[Math.floor(i * rate)] || 0;
}
}
// 此时 audioBuffer 就是变速后的音频数据
// 你可以用来播放,或者上传,或者下载
});
上面代码中的audioBuffer就是就是变速后的音频数据,你可以用来播放,或者上传,或者下载,具体如何实现,可参见之前“纯JS实现多个音频的拼接或者合并”一文。
代码一跑,嘿嘿,时长符合预期,但是竖起耳朵一听,不对劲,很不对劲,这声音的音调怎么变了。
慢速的时候声音变得特别的低沉,快速的时候音调非常高。
大家也可以来感受下,您可以狠狠地点击这里:JS音频倍速后音调发生变化demo
比方说demo页面中这段“斗气化马”的录音,两倍速后,声音听起来就像是捏着嗓子的孩童音。
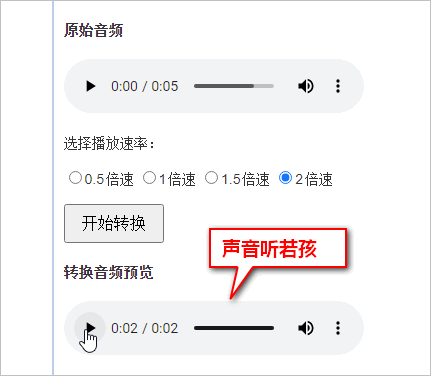
怎么回事,难道是代码逻辑有问题。
于是花时间研究了一番,发现事情不简单。
二、变速变音调的原因解密
众所周知,声音其实就是一种波,在数学上常常用三角函数表示。
播放速率变快,也就意味着波形越陡峭,自然音调也就越高。
下面这个GIF动图很好地示意了这一点(原图访问这里):
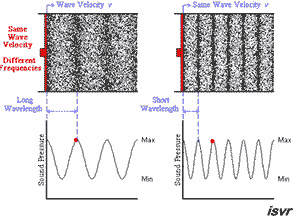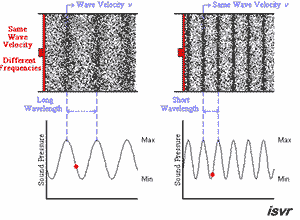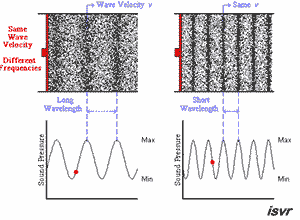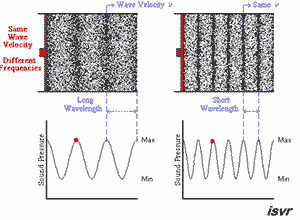
此图源自非常优质的一片外文“Everything You Should Know About Sound”,可以加深大家对音频本质的了解。
如何解决?
音频拉伸影响音调其实是业界比较知名的一个问题了,非常考验算法功力,所以各路大神分分出马,诞生了很多经典的算法。
例如颗粒合成(Granular synthesis)算法,大致原理是这样的。
音频采样是一个一个的点,这些点连在一起,就会构成波峰或曲线,为了方便示意,我们用一条直线代替,如下所示:
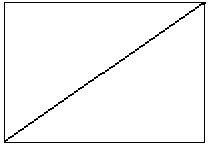
现在缩短音频播放时长,也就是加快音频的播放速率,那么采样点曲线就会变得更加陡峭,就会是这样子:
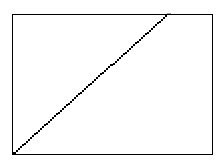
陡峭也就意味着音调变高了,显然不是我们想要的,所以需要保持速率的同时让曲线不陡峭,可以这么处理,把曲线截成一段一段的颗粒,让这段颗粒的曲度和默认播放曲线一致,然后这些颗粒的起点位置偏移,保持设定的播放速率,就像下图这样:
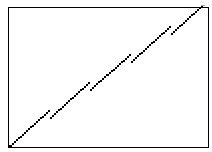
于是,用户听起来播放速度快了,同时音调并未发生变化。
当然,还有很多其他的算法,我并未去深究。
这些算法本质上是数学计算,有些还牵扯到傅里叶变换,而这些知识,我早已经还给教授了,所以,当机立断,找别人写好的算法,直接套用实现。
三、某个简单的算法实现
一开始找的是这个项目,原因无他,代码少,如何使用一目了然,参见:https://github.com/danigb/timestretch
其算法代码不多,直接粘贴出来都可以:
/**
* https://github.com/danigb/timestretch/blob/master/lib/index.js
* Copy `len` bytes generated by a function to `array` starting at `pos`
*/
function copy (len, array, pos, fn) {
for (var i = 0; i < len; i++) {
array[pos + i] = fn(i)
}
}
function stretch (ac, input, scale, options) {
// OPTIONS
var opts = options || {}
// Processing sequence size (100 msec with 44100Hz sample rate)
var seqSize = opts.seqSize || 4410
// Overlapping size (20 msec)
var overlap = opts.overlap || 882
// Best overlap offset seeking window (15 msec)
// var seekWindow = opts.seekWindow || 662
// The theoretical start of the next sequence
var nextOffset = Math.round(seqSize / scale)
// Setup the buffers
var numSamples = input.length
var output = ac.createBuffer(1, numSamples * scale, input.sampleRate)
var inL = input.getChannelData(0)
var outL = output.getChannelData(0)
// STATE
// where to read then next sequence
var read = 0
// where to write the next sequence
var write = 0
// where to read the next fadeout
var readOverlap = 0
while (numSamples - read > seqSize) {
// write the first overlap
copy(overlap, outL, write, function (i) {
var fadeIn = i / overlap
var fadeOut = 1 - fadeIn
// Mix the begin of the new sequence with the tail of the sequence last
return (inL[read + i] * fadeIn + inL[readOverlap + i] * fadeOut) / 2
})
copy(seqSize - overlap, outL, write + overlap, function (i) {
// Copy the tail of the sequence
return inL[read + overlap + i]
})
// the next overlap is after this sequence
readOverlap += read + seqSize
// the next sequence is after the nextOffset
read += nextOffset
// we wrote a complete sequence
write += seqSize
}
return output
}
使用非常简单,几行代码的事情,示意如下(假设原音频数据对象是 audioBuffer,播放速率是rate):
// 倍速变化,返回新的AudioBuffer
const newAudioBuffer = stretch(new AudioContext(), audioBuffer, 1 / rate, {
seqSize: audioBuffer.sampleRate / 10,
overlap: audioBuffer.sampleRate / 100
});
上面代码返回的newAudioBuffer就是倍速处理后的新的音频。
我们来看看这段代码真实应用后的效果,您可以狠狠地点击这里:JS音频倍速采用音调保持不变简易算法demo
还是斗气化马的音频,2倍速,细细听一下,可以听出是我的声音,可却有很多噪点杂音,听起来并不舒服:
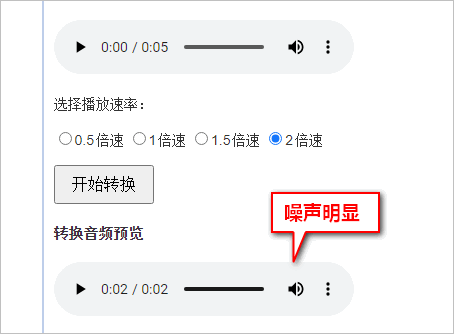
跑了下音频波形图,诸多细节丢失,很多地方过于平滑,感觉像是有些高音调的采样数据没能调好,混在一起,就好似噪点这般。
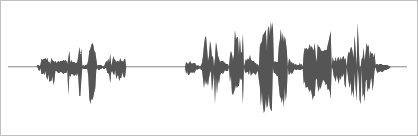
我琢磨着,会不会是因为我录音的时候,本身就有背景噪音导致,于是,就使用生产环境的AI语音进行测试。
我嘞个擦,正常声音的背后还有一道连续不断的刺耳的重金属噪音。
结论很明显,虽然此项目算法简单,但是效果真的是差,不能用在真实的项目中。
作者似乎也意识到自己这段代码的算法不是很牛逼的那种,于是有说:
This is not the best implementation if you’re looking for sound quality and/or performance (see FAQ).
如果您正在寻找音质和/或性能,这不是最好的实现(请参阅FAQ)。
而此项目的FAQ正好收罗了诸多音频时间拉伸算法,我差不多都研究了下,随后决定使用 OLA-TS.js 。
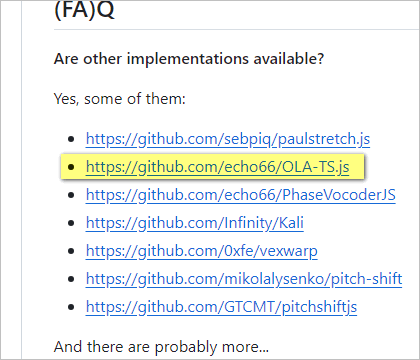
四、声音质量更好OLA算法实现
项目地址:https://github.com/echo66/OLA-TS.js
作者是这么描述的:
OLA-TS.js是一种改进的重叠和添加(OLA)算法的音频时间拉伸实现。
一番使用下来,效果确实好。
如何使用?
此项目非常老,年久失修,要是无人指引,想要上手还是要费一番功夫的。
经过我的一番整合,调试,终于弄了个可用的版本(原本的实现只支持多通道音频)。
很简单,首先,引入bufferedOla.js:
import BufferedOLA from './bufferedOla.js';
然后,通用下面的语法进行音频拉伸处理(假设原音频数据对象是 audioBuffer,播放速率是rate):
// 创建新的audiobuffer const newAudioBuffer = new AudioContext().createBuffer( audioBuffer.numberOfChannels, audioBuffer.length / rate, audioBuffer.sampleRate, ); const myOLATS = new BufferedOLA(); myOLATS.set_audio_buffer(audioBuffer); myOLATS.alpha = 1 / rate; myOLATS.process(newAudioBuffer);
执行完上面的代码后,newAudioBuffer就是处理后的倍速音频AudioBuffer数据了。
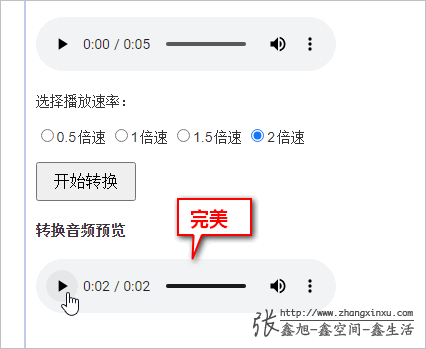
眼见为实,您可以狠狠地点击这里:JS音频时间拉伸改进算法demo
此时,再去2倍速听“斗气化马”,喔噢,没有任何杂音,非常流畅,非常完美。
五、结束说明
看看时间,12点之前写不完了,前段时间感冒发烧,家里领导规定必须12点之前关机休息,写到这里23:53,加上还要配图,写摘要,写关键字,社交账号写周知消息,12点之前定是来不及了。
保存草稿,明天发布,断更就断更吧,身体要紧。
最后,附上那些与音频时间速率音调相关的项目:
- https://github.com/sebpiq/paulstretch.js
- https://github.com/echo66/OLA-TS.js
- https://github.com/echo66/PhaseVocoderJS
- https://github.com/Infinity/Kali
- https://github.com/0xfe/vexwarp
- https://github.com/mikolalysenko/pitch-shift
- https://github.com/GTCMT/pitchshiftjs
全都是很多年之前的项目了,就这样,我们下篇文章再见。
😀😃
😄😁
😆😀
本文为原创文章,欢迎分享,勿全文转载,如果实在喜欢,可收藏,永不过期,且会及时更新知识点及修正错误,阅读体验也更好。
本文地址:https://www.zhangxinxu.com/wordpress/?p=11124
(本篇完)